欢迎来到 XTuner V1 的中文文档#
LLM 一站式工具箱
XTuner V1 是一个专为超大规模 MoE 模型打造的新一代大模型训练引擎。与传统 3D 并行训练架构相比,XTuner V1 针对当前学术界主流的 MoE 训练场景进行了深度优化。
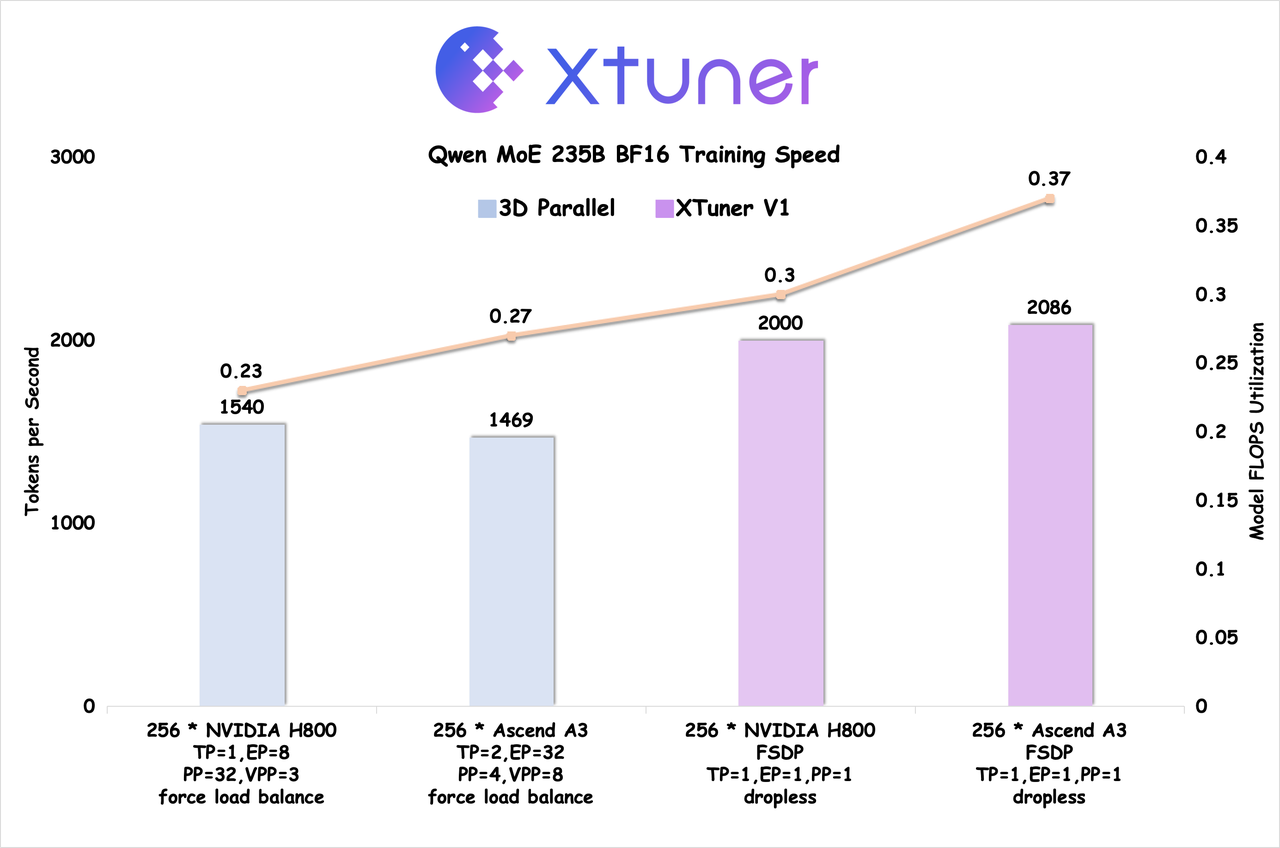
🚀 Speed Benchmark#
核心特性#
📊 Dropless 训练
灵活扩展,无需复杂配置: 200B 量级 MoE 无需专家并行;600B MoE 仅需节点内专家并行
优化的并行策略: 相比传统 3D 并行方案,专家并行维度更小,实现更高效的 Dropless 训练
📝 长序列支持
内存高效设计: 通过先进的显存优化技术组合,200B MoE 模型无需序列并行即可训练 64k 序列长度
灵活扩展能力: 全面支持 DeepSpeed Ulysses 序列并行,最大序列长度可线性扩展
稳定可靠: 长序列训练时对专家负载不均衡不敏感,保持稳定性能
⚡ 卓越效率
超大规模支持: 支持高达 1T 参数量的 MoE 模型训练
突破性能瓶颈: 首次在 200B 以上规模的 MoE 模型上,实现 FSDP 训练吞吐超越传统 3D 并行方案
硬件优化: 在 Ascend A3 NPU 超节点上,训练效率超越 NVIDIA H800
🔥 Roadmap#
XTuner V1 致力于持续提升超大规模 MoE 模型的预训练、指令微调和强化学习训练效率,并重点优化昇腾 NPU 支持。
🚀 训练引擎#
我们的愿景是将 XTuner V1 打造成通用训练后端,无缝集成到更广泛的开源生态系统中。
Model |
GPU(FP8) |
GPU(BF16) |
NPU(BF16) |
|---|---|---|---|
Intern S1 |
✅ |
✅ |
✅ |
Intern VL |
✅ |
✅ |
✅ |
Qwen3 Dense |
✅ |
✅ |
✅ |
Qwen3 MoE |
✅ |
✅ |
✅ |
GPT OSS |
✅ |
✅ |
❌ |
Deepseek V3 |
✅ |
✅ |
❌ |
KIMI K2 |
✅ |
✅ |
❌ |
🧠 算法套件#
算法组件正在快速迭代中。欢迎社区贡献 - 使用 XTuner V1,将您的算法扩展到前所未有的规模!
已实现
✅ 多模态预训练 - 全面支持视觉语言模型训练
✅ 多模态监督微调 - 针对指令跟随优化
✅ GRPO - Group Relative Policy Optimization
即将推出
⚡ 推理引擎集成#
与主流推理框架无缝对接
✓ LMDeploy
✗ vLLM
✗ SGLang
🤝 贡献指南#
我们感谢所有的贡献者为改进和提升 XTuner 所作出的努力。请参考 贡献指南 来了解参与项目贡献的相关指引。
🙏 致谢#
XTuner V1 的开发深受开源社区优秀项目的启发和支持。我们向以下开创性项目致以诚挚的谢意:
训练引擎:
[Torchtitan](pytorch/torchtitan) - PyTorch 原生分布式训练框架
[Deepspeed](deepspeedai/DeepSpeed) - 微软深度学习优化库
[MindSpeed](https://gitee.com/ascend/MindSpeed) - 昇腾高性能训练加速库
[Megatron](NVIDIA/Megatron-LM) - NVIDIA 大规模 Transformer 训练框架
强化学习:
XTuner V1 的强化学习能力借鉴了以下项目的优秀实践和经验
[veRL](volcengine/verl) - Volcano Engine Reinforcement Learning for LLMs
[SLIME](THUDM/slime) - THU’s scalable RLHF implementation
[AReal](inclusionAI/AReaL) - Ant Reasoning Reinforcement Learning for LLMs
[OpenRLHF](OpenRLHF/OpenRLHF) - An Easy-to-use, Scalable and High-performance RLHF Framework based on Ray
我们衷心感谢这些项目的所有贡献者和维护者,是他们推动了大规模模型训练领域的不断进步。
🖊️ 引用#
@misc{2023xtuner,
title={XTuner: A Toolkit for Efficiently Fine-tuning LLM},
author={XTuner Contributors},
howpublished = {\url{https://github.com/InternLM/xtuner}},
year={2023}
}
开源许可证#
该项目采用 Apache License 2.0 开源许可证。同时,请遵守所使用的模型与数据集的许可证。