数据流#
数据流总览#
XTuner 的数据流围绕四个核心组件展开:
JsonlDatasettokenize_fnPackDatasetcollate_fn
模块之间的数据流概览如下:
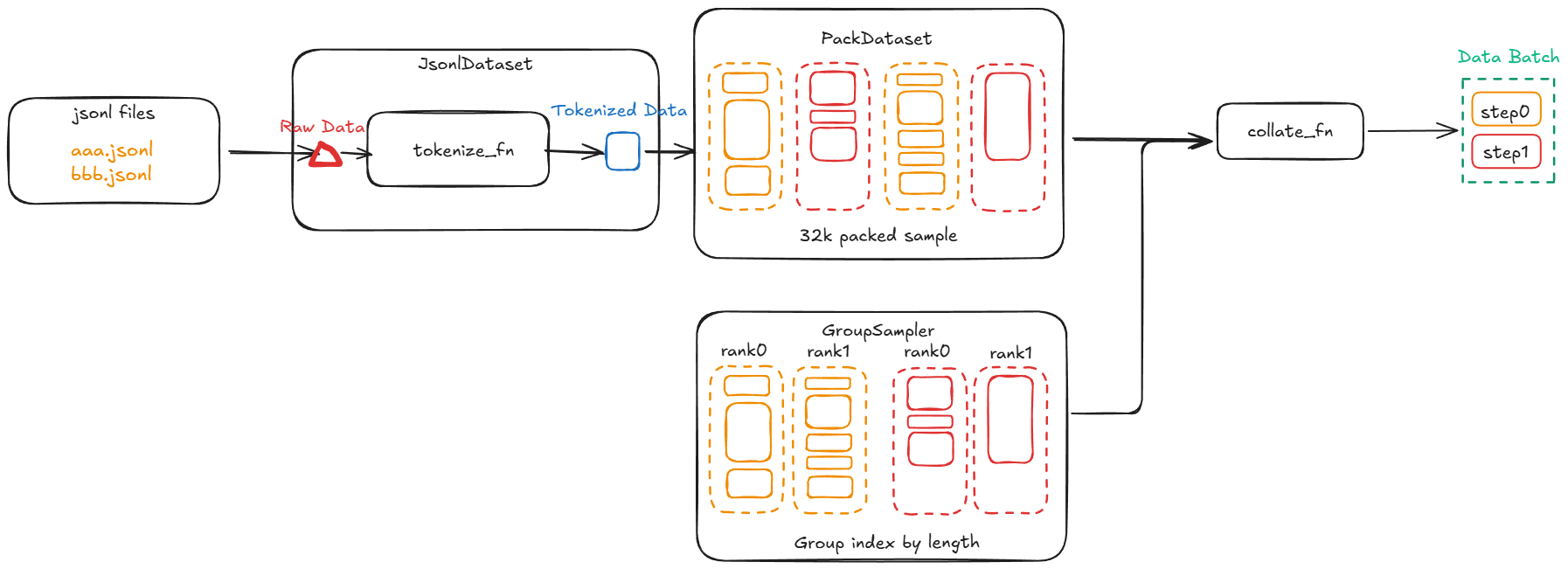
数据流概览#
在后面的章节里,我们会展开讲讲每一个模块的功能
JsonlDataset#
jsonl 格式的数据可读性良好,易于流式读取,因此 XTuner 实现了 JsonlDataset 来针对 jsonl 格式的数据实现分布式数据缓存。你或许会很好奇,jsonl 数据的格式本身就很简单,为什么要引入一套复杂的缓存机制呢?如果只是一个简单的数据流式读取,可能几行代码就能实现,然而实际需求往往会更加复杂。
样本均衡#
大规模训练的情况下,一个 step 的耗时取决于最慢 rank 的耗时。因此这就要求每个 rank 分发的数据尽可能均衡。举例来说,短序列组成的 batch 和长序列组成的 batch,二者在 attention 阶段的计算量是不同的。如果我们希望各个 rank 在同一个 step 上的耗时尽可能接近,就需要让每个 rank 上的数据在序列长度的分布上尽可能平衡。
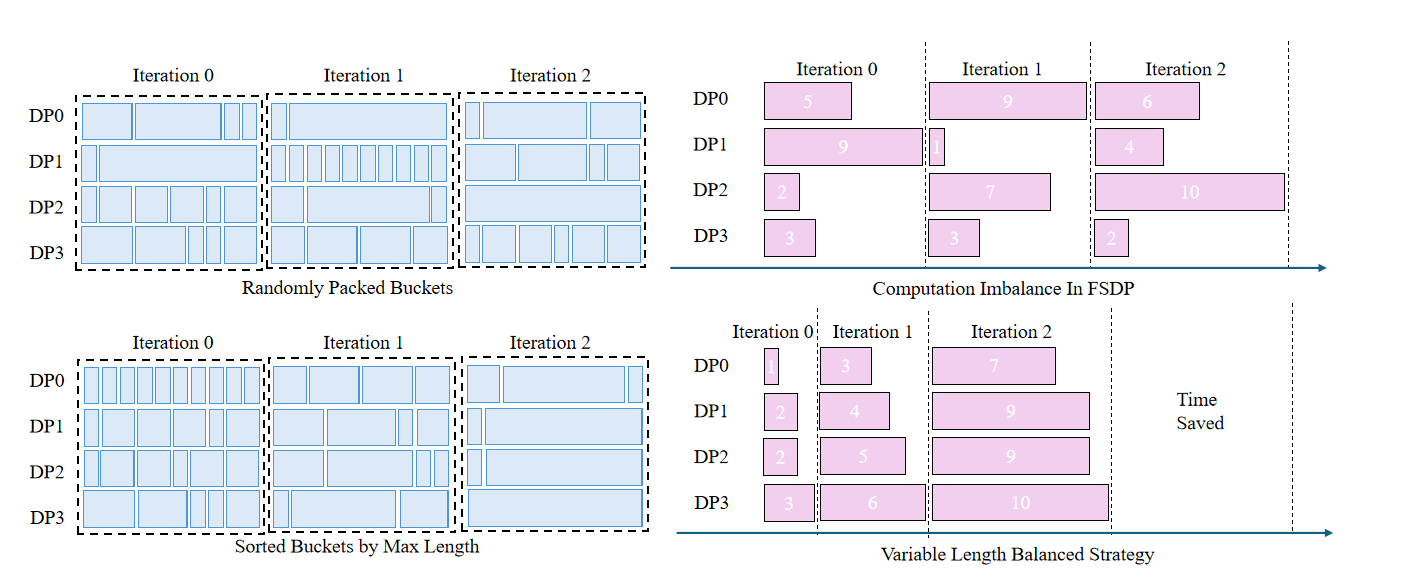
数据分组#
如何在不读取完整数据的情况下实现这样的功能呢?那就是缓存。XTuner 极致地利用了分布式训练的计算资源,在第一次训练之前缓存数据,以确保 sampler 能够获取 meta 信息对数据进行分组。
JsonlDataset 正承担了这一职责,具体流程如下:
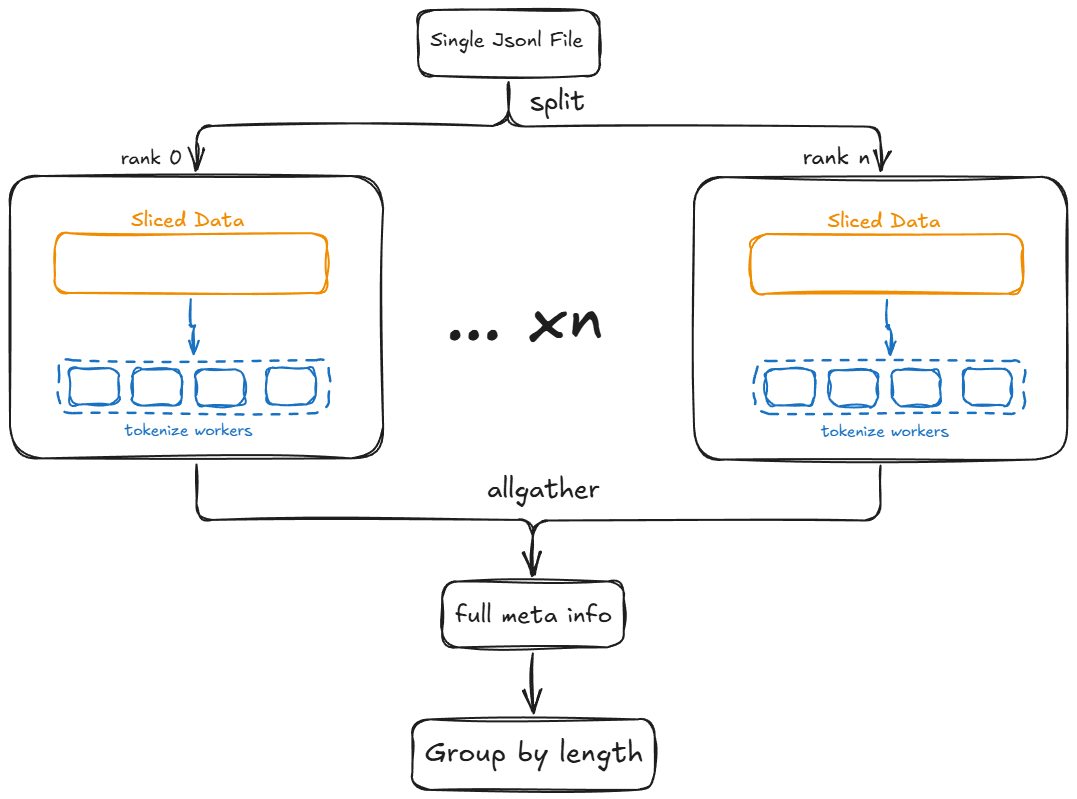
数据缓存#
具体来说,假设我们有一个 4 条数据的 jsonl 文件,并使用 2 卡训练,每张卡上的 tokenize_worker 数量为 2:
{"messages": [{"role": "user", "content": "hello"}, {"role": "assistant", "content": "hi hi"}]}
{"messages": [{"role": "user", "content": "hello"}, {"role": "assistant", "content": "hello hello hello hello"}]}
{"messages": [{"role": "user", "content": "hello"}, {"role": "assistant", "content": "hi hi hi hi"}]}
{"messages": [{"role": "user", "content": "hello"}, {"role": "assistant", "content": "hello hello"}]}
那么具体的数据分发逻辑如下:
rank0 |
rank1 |
|
|---|---|---|
tokenize_worker0 |
dataset[0] |
dataset[2] |
tokenize_worker1 |
dataset[1] |
dataset[3] |
最终并行处理完后,会 gather 成一个完整的 meta 信息:
[
{"num_tokens": 2},
{"num_tokens": 4},
{"num_tokens": 4},
{"num_tokens": 2},
]
这些 meta 信息会被后续的 packing、sample 环节用到,用来构建训练耗时均匀的样本。
缓存命中#
数据缓存应该只在第一次训练时触发,后续采用相同数据集+相同数据处理策略时,应该命中之前处理好的缓存。因此如何判断缓存是否命中就很关键。缓存是否命中其实和很多因素有关,包括但不限于:
数据文件是否命中
tokenize 过程是否命中
tokenizer 是否命中
对话模板是否命中
数据的最大长度是否命中
…
其中 JsonlDataset 只关心数据文件是否命中,至于 tokenize 的过程能否命中,则下发给具体的模块 TokenizeFn。这个模块的功能我们后续会详细展开,此处只需要知道,tokenize 过程是否命中是由这个模块自身的实现决定的:
from xtuner.v1.datasets import CachableTokenizeFunction
class CustomTokenizeFn(CachableTokenizeFunction):
def hash(self) -> str:
...
tokenize_fn#
上一节在介绍 JsonlDataset 的时候,我们引入了 TokenizeFn 的概念,那这一节我们就来进一步了解其承担的具体职责。
TokenizeFn 负责将 jsonl 里的数据处理成 input_ids 和对应的 labels。
数据协议#
输入:jsonl 里每一行数据
输出: model forward 需要用的数据(会在 collate_fn 里被整合,这部分后续再介绍):
纯文本训练:返回
{"input_ids": [...], "labels": [...]}多模态训练:以 VLLM 为例,除了
input_ids和labels字段之外,tokenize_fn需要额外返回pixel_values等字段
class MyTokenizeFn(CachableTokenizeFunction):
def __init__(self, tokenizer, max_length: int):
self.tokenizer = tokenizer
self.max_length = max_length
def __getitem__(self, data_item):
# `data_item`: single line data read from jsonl file.
# {"messages": [{"role": "user", "content": "hello"}, {"role": "assistant", "content": "hi hi"}]}
input_ids = self.tokenizer.apply_chat_template(data_item["messages"])[:self.max_length]
labels = ...
return {"input_ids": input_ids, "labels": labels}
缓存#
此外,为了实现上一节提到的缓存功能,TokenizeFn 还需要管理自身的 hash 值,即判断什么情况下,能(不能)触发缓存命中。以上述最简实现为例,tokenize 之后的结果只和 tokenizer 和 max_length 有关:
from xtuner.v1.datasets import CachableTokenizeFunction
class MyTokenizeFn(CachableTokenizeFunction):
def hash(self) -> str:
if self._hash is None:
_tokenizer_hash = tokenizer_xxhash(self.tokenizer)[:16]
self._hash = _tokenizer_hash
return self._tokenizer_hash + str(self.max_length)
else:
return self._hash
此外,对于 VL 之类的模型,缓存阶段仅需要数据的 meta 信息即可完成均衡的数据采样,因此 TokenizeFn 也会被进一步区分成 2 种状态,其中 cache 模式只不读图,只抽取 meta 信息,runtime 模式才会触发图片的真实读取:
class MyTokenizeFn(CachableTokenizeFunction):
def __getitem__(self):
if self.state == "cache":
...
else:
...
其中 JsonlDataset 在初始化阶段,TokenizeFn 的 state 会切换为 cache。训练阶段读取数据时,则会切换为 runtime。用户可以按需选择是否要区分 cache 和 runtime 来实现 TokenizeFn。
PackDataset#
对于大型语言模型(LLM)的输入而言,数据打包 (Packing) 这一概念指的是将多个 token 序列拼接成一个单独的输入。大量的数据集都存在一个特点,即其长度分布严重偏向较短的序列,而 Transformers 模型接收固定长度的输入。因此,传统 (batch_size, seq_len, hidden_size) 形状的输入会导致 seq_len 维度存在大量的 Pad Token。而 “Pad Token” 往往是某个特定的无意义的 token,浪费计算资源。
将多条数据打包 (Packing) 在一起可以大量减少 “Pad Token”,提高计算利用率。
目前 XTuner 支持 2 种 Packing 策略,即 SoftPack 和 HardPack:
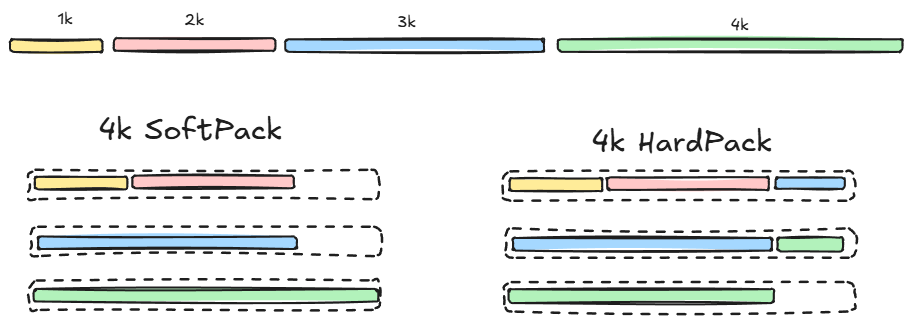
数据打包#
SoftPack: 非截断地拼接样本到
max_lengthHardPack: 截断式地将样本拼接到
max_length
Pack 之后的样本(PackedSample)会直接用于模型的训练。
备注
PackDataset 只负责规划哪些样本会被 pack 到一起,具体的 pack 行为发生在 collate_fn 里。
大部分情况下,用户不需要感知到 PackDataset,只需要正确地实现 TokenizeFn,在缓存阶段让数据返回 input_ids 和 labels,就可以自动触发 packing 的逻辑。
from xtuner.v1.datasets.config import DataloaderConfig
dataloader_config = DataloaderConfig(pack_level="soft")
# dataloader_config = DataloaderConfig(pack_level="hard")
LengthGroupedSampler#
JsonlDataset 一节我们引入了训练样本均衡这一概念,为了达成这一目标,XTuner 实现了 LengthGroupedSampler,根据样本长度对训练的 PackedSample 进行分组。
具体来说,PackDataset 会在 Packing 阶段记录下一些 PackedSample 的元信息,方便后续阶段根据计算开销进行 Group。例如 attention 部分的计算开销会和下三角矩阵的面积呈正相关,那么我们就会在 Pack 阶段把这个指标记录下来,在 LengthGroupedSampler 里对其进行分组。
分组过程遵循以下原则:
局部分组,分组行为只在局部生效,确保样本分布的全局随机性
组内按照计算开销排序,保证每个 rank 分配到的样本均衡
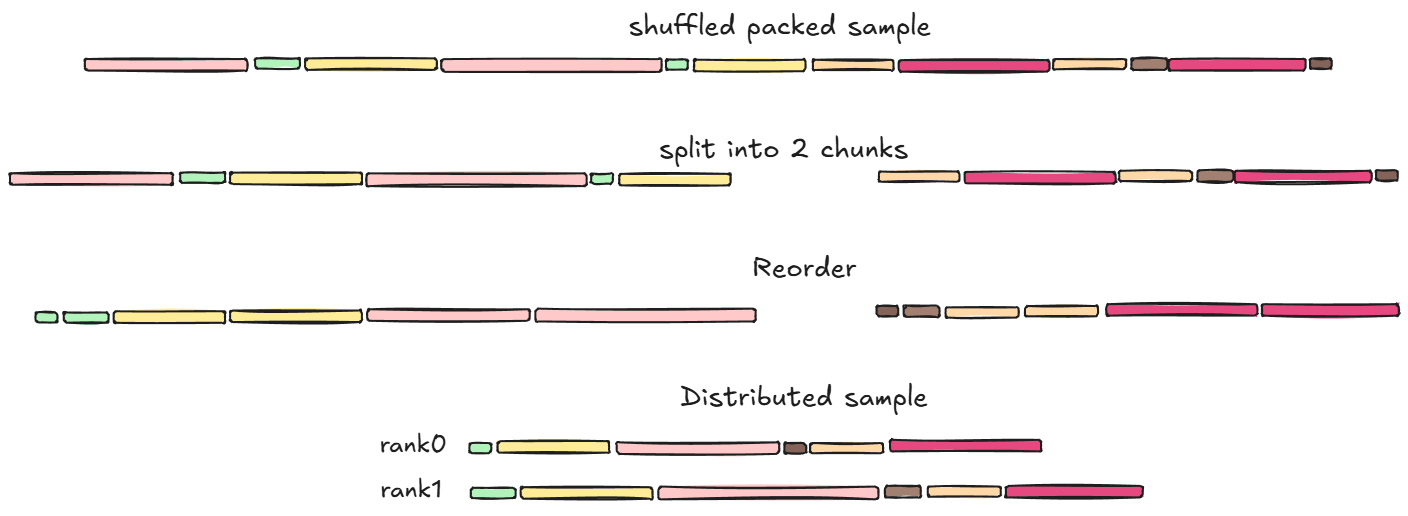
数据分组实现#
collate_fn#
collate_fn 语义和 torch Dataloader 的入参 collate_fn 保持一致,主要功能是对 batch 数据的整合。XTuner 在 collate_fn 里会将数据打包成 batch of SequenceContext,即模型 forward 阶段依赖的数据结构。
正如流程概览图里所示,collate_fn 接收的是 PackDataset 索引出来的结果,这也就意味着其输入的 batch_data 会有 2 层嵌套列表:
第一层列表:表示梯度累加的第几个 batch
第二层列表:表示
PackedSample有几个样本
一个 SequenceContext 对应一个 PackedSample,我们需要将数据信息拼接后,构建 SequenceContext。以 LLM 训练为例:
def custom_collator(
instances: list[list[DataItem]], pack_max_length: int, padding_token_idx: int, pack_to_max_length: bool = True
) -> list[ColateItem]:
ret: list[ColateItem] = []
for instance in instances:
seq_ctx, shifted_labels = build_text_ctx_labels(
instance,
pack_max_length,
padding_token_idx,
pack_to_max_length,
)
ret.append(
{
"seq_ctx": seq_ctx,
"shifted_labels": shifted_labels,
}
)
return ret
如果想扩展一些字段,可以自定义类扩展 SequenceContext:
class CustomSequenceContext(SequenceContext):
def __init__(...):
...
# Optional: For Sequence Paralllel
def split(self, sequence_parallel_mesh: DeviceMesh | None = None) -> Self:
...
# Optional: For intralayer training
@classmethod
def cat(cls, sequence_context_list: list["SequenceContext"]) -> "SequenceContext":
...
def custom_collator(
instances: list[list[DataItem]], pack_max_length: int, padding_token_idx: int, pack_to_max_length: bool = True
) -> list[ColateItem]:
ret: list[ColateItem] = []
for instance in instances:
seq_ctx, shifted_labels = build_text_ctx_labels(
instance,
pack_max_length,
padding_token_idx,
pack_to_max_length,
)
# 基于 instance 构建新的 `seq_ctx`
seq_ctx = CustomSequenceContext(
**seq_ctx.data,
...
)
ret.append(
{
"seq_ctx": seq_ctx,
"shifted_labels": shifted_labels,
}
)
return ret