数据集#
在开始本教程之前,推荐先前置阅读以下任一文档:
数据缓存#
在之前的教程中你或许会发现,使用同一个数据集启动多次训练时,XTuner 默认每次都会花一些时间加载数据集。对于小数据集来说,这个时间可能不明显,但如果你的数据集非常大,每次的训练启动时间将是一场灾难。
事实上,这个加载过程主要是对数据集进行预处理,对训练样本进行一些长度统计,方便控制训练时的采样顺序,提升训练阶段的效率。具体流程如下:
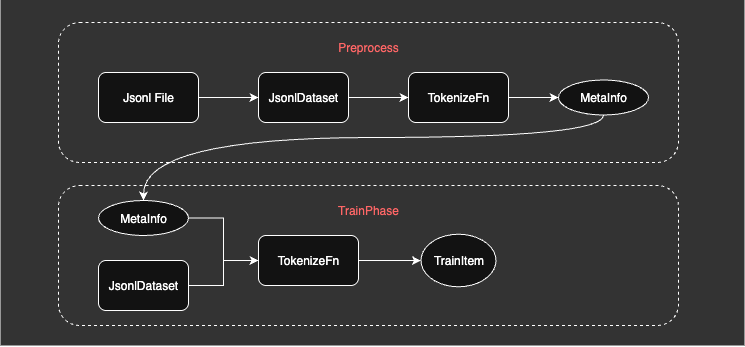
数据预处理#
由于这个预处理流程是可缓存的,因此 XTuner 为 dataset 提供了缓存功能,使得预处理过一次的数据集可以被重复利用,极大幅度的减少二次启动耗时。
from xtuner.v1.datasets import DatasetConfig
dataset_cfg = DatasetConfig(
cache_dir='work_dirs/dataset_cache', # 指定缓存目录
)
具体来说,缓存功能会根据以下几个条件判断缓存是否命中:
jsonl文件本身的 hashtokenize_fn对应的源码实现tokenizer本身的 hash
一旦上述任一条件不满足,缓存都会失效,重新处理数据集。严格的缓存检查机制固然能保证缓存的正确性,但是也会带来一些不便,例如你正在 debug 数据处理函数,频繁地修改源码。然而此时你又不希望每次都重新触发数据的缓存,导致迟迟无法进入到你关心的断点。
为了避免这种情况发生,你可以在指定缓存目录的同时指定 cache_tag,使得只要 cache_tag 不变,缓存就一直命中。
dataset_cfg = DatasetConfig(
cache_tag='v0.0.1', # 指定缓存目录
)
自定义数据集#
在之前的教程中,我们了解了如何使用 XTuner 预支持的数据集格式进行训练。那如果我们有自定义的数据格式、对话模板,该怎么办呢?本节将带你了解如何编写自定义数据集的处理函数,并将其应用于微调训练中。
备注
要支持 jsonl 以外格式的数据集会更复杂,可以参考进阶教程,
目前 XTuner 只支持 jsonl 格式的数据集,要求每一行必须是一个合法的 JSON 对象。默认的 TokenizeFnConfig.build 会构建出一个 TokenizeFn 用于将 jsonl 里的每一行数据解析成符合 XTuner 数据协议的格式。那什么是合法的 XTuner 数据协议呢?其实很简单,只需要 TokenizeFn 返回一个包含以下字段的字典即可:
{
'input_ids': [...], # 输入的 token id 列表,用于实际训练
'labels': [...], # 未经偏移的 labels,长度和 `input_ids` 一致,不算 loss 的位置用 -100 填充
'num_tokens': ... # 当前样本有多少个 token,方便用于基于长度的均衡采样
}
因此想要解析自定义的数据格式、使用自定义的对话我们,我只需要实现一个 TokenizeFnConfig 即可,让他的 build 方法返回一个符合 TokenizeFn 接口协议的可调用对象即可。例如我们想解析以下格式的 json 文件:
:caption: 自定义 json 格式
{"instruction": "请介绍一下你自己。", "output": "我是一个由人工智能驱动的语言模型,旨在帮助用户解决各种问题。"}
{"instruction": "什么是人工智能?", "output": "人工智能(Artificial Intelligence,AI)是指通过计算机系统模拟人类智能的技术和方法。"}
我们可以实现一个 MyTokenizeFnConfig 来解析上述格式:
from pydantic import BaseModel
from xtuner.v1.datasets import CachableTokenizeFunction, tokenizer_xxhash
class MyTokenizeFn(CachableTokenizeFunction):
# 由 `TokenizeFnConfig.build` 构建,会传入 tokenizer
def __init__(self, tokenizer, max_length=2048):
self.tokenizer = tokenizer
self.max_length = max_length
self._hash = None
# item 是 jsonl 里的一行数据,已经被解析成字典
def __call__(self, item):
instruction = item['instruction']
output = item['output']
input_ids = self.tokenizer.encode(f"Instruction: {instruction}\nResponse: {output}", add_special_tokens=True)
input_ids = input_ids[:self.max_length]
labels = input_ids
num_tokens = len(input_ids)
return {"input_ids": input_ids, "labels": labels, "num_tokens": num_tokens}
# 这个 hash 用于数据缓存,当 max_length 或者 tokenizer 变化时,需要重新触发缓存
def hash(self):
if self._hash is None:
self._hash = f"{tokenizer_xxhash(self.tokenizer)}_{self.max_length}"
return self._hash
class MyTokenizeFnConfig(BaseModel):
max_length: int = 2048
def build(self, tokenizer, **kwargs):
return MyTokenizeFn(tokenizer, max_length=self.max_length)
之后,我们只需要在配置文件中引用这个 MyTokenizeFnConfig 即可:
from cusomt_tokenize_fn import MyTokenizeFnConfig
dataset_cfg = [
{
...
"tokenize_fn": MyTokenizeFnConfig(max_length=2048), # 使用自定义的 TokenizeFnConfig
},
]
重要
不建议在配置文件里直接实现TokenizeFnConfig,而是放在单独的 python 文件里,然后在配置文件中引用。配置和代码实现应该分离,有助于实验管理和代码维护