Megatron MoE训练benchmark及调优指南#
大模型训练速度调优思路#
首先解决显存问题#
在大规模模型训练中,必须进行模型并行切分来解决显存问题,但过度切分会影响单卡的计算量。因此,我们的首要目标是尽量提高单卡计算量,主要手段是合理控制并行度,避免过度切分。
在分析并行策略之前,我们先了解显存的主要组成部分:参数、梯度、混合精度的Master参数和梯度、优化器状态以及激活值。
Megatron目前支持各种并行策略,他们该如何选择呢?
Zero1是必选项,它有效地降低了优化器状态占用的大量显存,并且通信量低可扩展性好。在大模型训练时,通常都会做多次梯度累积(即有较大的micro batch数目)才做一次梯度聚合,zero1在这样的场景上并不会引入很大开销。但是其他策略各有优劣。
TP(张量并行):
显存效果:能够高效降低显存占用,参数、梯度、优化器状态、激活值(同时开启sequence_parallel时)全部等比例减少
计算量:单卡计算量等比例减少
计算和通信效率:由于通信量大、矩阵被切分变小等原因,即使采用overlap策略,计算效率仍会降低
建议:在显存不够时,才开启带sequence_parallel的TP,其他情况不开启
PP(流水线并行):
显存效果:不会减少激活值显存(目前有ZB-Half、PipeOffload等技术探索PP进一步减少显存,值得关注)
计算量:单卡计算量等比例减少
计算和通信效率:通信量相对较少,不会减少kernel中矩阵乘法计算规模,因此计算效率较高
建议:PP有很好的扩展性,建议优先使用。但是PP也不适宜过大,一方面降低了单卡计算量,另一方面PP大时必须同步增加micro batch数目(也就增大了global batch size)以降低流水线气泡。
EP(专家并行):
显存效果:不会减少激活显存,也不会减少Attention模块的显存占用
计算量:开启EP不会降低单卡计算量
【EP的两面性】计算和通信效率:缺点是通信量较大,还会引入EP负载不均衡问题;优点是会增大单个专家的输入batch大小,提高计算密度(这也是上条计算量不减少的原因)。为了解决EP缺点,出现了DualPipe、带loss和不带loss的负载均衡等技术。
建议:计算效率可能提高也可能降低,需要根据具体情况进行权衡。
第二目标计算打满#
在解决了显存问题后,我们需要通过多种手段来实现计算资源的充分利用,确保GPU的计算能力得到最大化发挥。主要优化手段包括:
通信重叠优化:
Zero1通信重叠:将优化器状态的通信与反向传播计算重叠,减少通信等待时间
TP通信重叠:在张量并行中将AllGather、ReduceScatter等通信与计算操作重叠执行
PP通信重叠:在流水线并行中将P2P通信与计算重叠,提高流水线效率
EP A2A通信重叠:在专家并行中将All-to-All通信与其他计算操作重叠
提升计算强度:
合理控制并行度:如前文所述,通过尽量减少不必要的并行切分来提高单卡的计算量,避免过度分割导致的计算资源浪费
增大计算单元的计算强度:通过算子融合,优化矩阵乘法的规模和批次大小等手段,来减少内存访问开销,提高计算核心的利用率
控制PP气泡率:合理设置micro batch数量,确保流水线各阶段的负载均衡,减少流水线气泡时间
解决负载不均衡问题:
PP负载不均衡:确保各流水线阶段的计算量相对均衡
EP负载不均衡:优化专家路由策略,避免某些专家过载而其他专家空闲
参数调优:精细调整MicroBatchSize, SeqLen, Recompute, Offload等参数来平衡内存使用和计算效率,以达到最佳性能
注意单独使用Recompute相比基线速度肯定会下降,但是如果开启Recompute能够关掉TP,或者MicroBatchSize增大,那么就有可能通过提高计算强度来弥补recompute开销,从而提高整体速度
Megatron训练Qwen3-235B-A22B MoE模型调优实战及Benchmark结果#
环境说明#
环境:H800 256卡 代码基于Pai-Megatron-Patch Commit id: 2b201af 镜像:dsw-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pai-megatron-patch:25.04
配置同官方Qwen3示例脚本,其他不同配置如下
recompute=select 是指重计算layernorm和moe中swiglu,类似DeepSeekV3的做法,引入很小的重计算量但是可以省掉一部分激活值显存: --recompute-granularity selective --recompute-modules moe_act layernorm
recompute=moe 是指重计layernorm和moe整个模块: --recompute-granularity selective --recompute-modules moe layernorm
如果开启TP,都开启 --sequcen_parallel
如果未指明,则默认 MicroBatchSize mbs=1 : --micro-batch-size 1
开启zero overlap: --overlap-grad-reduce --overlap-param-gather
为了测速开启moe强制均衡: --moe-router-force-load-balancing
关闭cuda graph,即去掉 : --external-cuda-graph --cuda-graph-scope attn
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True,pinned_use_cuda_host_register:True
其他设置:
--manual-gc --manual-gc-interval 5
--cross-entropy-fusion-impl te
--num-workers 4 --no-mmap-bin-files --no-create-attention-mask-in-dataloader
--moe-permute-fusion
TP vs PP:优先PP,显存不够再考虑TP#
实验结果:
配置 |
SeqLen |
GlobalBatchSize |
GPUNum |
TimePerIter (s) |
Tokens/GPU/Second |
|---|---|---|---|---|---|
tp2, ep8, pp32, vpp3, mbs=1, recompute=select |
4096 |
2048 |
256 |
22.42 |
1461.56 |
tp4, ep8, pp8, vpp4, mbs=1 |
4096 |
2048 |
256 |
35.481 |
923.53 |
这两个配置的重点区别在于TP设置不同,TP2的配置明显快于TP4。这印证了上文的建议:尽量少开TP。
那能不能不开TP呢?
在我们当前 256卡 训练 235B模型的场景下,如果要求不开recompute(recompute=select也近似于不开recompute),那么就必须开TP,否则会超过单卡显存。
这是因为PP和EP都不减少激活值的显存,只有开启sequcen_parallel的TP能够高效降低激活值显存。而激活值显存是显存的大头。下面来看具体的案例分析。
我们对上面两个Qwen3 235B MoE的训练配置,通过理论计算出单个GPU上显存总量和各部分占比来做显存案例分析。
首先按显存类型维度来看,即看参数、梯度、混合精度的Master参数和梯度、优化器状态以及激活值的占比。
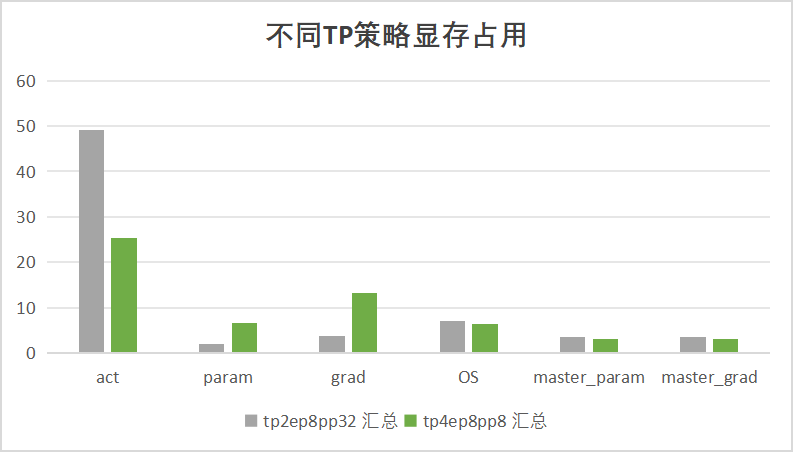
不同TP策略显存占用#
从上图可以发现,得益于比较大的并行数,以及zero1策略,模型参数、梯度、优化器等显存占比都较小。在这个场景下,激活值是显存的大头。 而从上节的分析中可以知道,无论是流水线并行、还是专家并行都无法降低激活值显存。因此只能通过TP(开sequence_parallel) 来降低激活值显存,从而让单个H800显存承受住235B模型的训练。
另外顺便按Attention、MLP模块维度,看下上面两个策略的显存占比,可以知道MLP模块占大头。
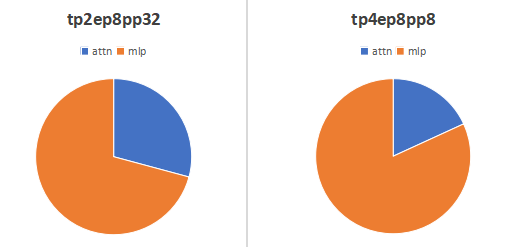
不同TP策略显存占用#
尝试不同EP设置#
配置 |
SeqLen |
GlobalBatchSize |
GPUNum |
TimePerIter (s) |
Tokens/GPU/Second |
|---|---|---|---|---|---|
tp2, ep32, pp8, vpp4, recompute=select |
4096 |
2048 |
256 |
35.392 |
925.87 |
tp2, ep32, deepep, pp8, vpp4, recompute=select |
4096 |
2048 |
256 |
25.73 |
1273.54 |
tp2, ep8, pp32, vpp3, mbs=1, recompute=select |
4096 |
2048 |
256 |
22.42 |
1461.56 |
比较前两个实验,同样是ep32,可以看到使用DeepEP可以大幅提速,这可以减少EP通信的时间,弥补这方面的缺点。
比较后两个实验,ep32 pp8并且开了DeepEP 比 ep8 pp32慢,说明虽然ep增大,提升了Group GEMM的计算强度,但是带来的All to All通信极大影响了训练效率。 目前Megatron还没有类似DeepSeek中DualPipe这种隐藏All to All通信的技术,不过Megatron团队正在研发一个基于Interleaved 1F1B的A2A overlap技术,可以参考他们的这个博客。
尝试通信重叠#
首先看 zero overlap 和 tp overlap的实验结果。
配置 |
SeqLen |
GlobalBatchSize |
GPUNum |
TimePerIter (s) |
Tokens/GPU/Second |
|---|---|---|---|---|---|
tp2, ep8, pp8, recompute=select |
4096 |
2048 |
256 |
27.555 |
1189.17 |
tp2, ep8, pp8, recompute=select, zero overlap |
4096 |
2048 |
256 |
29.66 |
1104.8 |
tp2, ep8, pp8, recompute=select, zero/tp overlap |
4096 |
2048 |
256 |
29.276 |
1119.26 |
前两个实验可以看到 zero overlap 并没有明显变化,这是因为当前梯度累积次数为 GlobalBatchSize / DP / MBS = 2048 / 16 / 1 = 128 ,也就是做128次前向和反向才做一次zero通信,所以这不是当前速度的瓶颈。 后两个实验可以看到 tp overlap 也没有明显变化,这是因为 tp overlap开启后虽然tp通信被重叠,但是相关的矩阵乘规模更小降低了计算效率,两者抵消所以变化不大。此时如果TP进一步变大,矩阵乘规模更小,反而会让速度下降。类似的情况在用于长序列的Context Parallel中也会发生。
下面看 pp overlap的实验。
配置 |
SeqLen |
GlobalBatchSize |
GPUNum |
TimePerIter (s) |
Tokens/GPU/Second |
|---|---|---|---|---|---|
tp2, ep8, pp32, vpp3, mbs=4, recompute=full |
4096 |
4096 |
256 |
43.495 |
1506.76 |
tp2, ep8, pp32, mbs=4, recompute=full |
4096 |
8192 |
256 |
92.652 |
1414.68 |
在Megatron中只有开启 virtual pipeline parallel(即interleaved 1F1B)才能做流水线中的通信重叠。一方面有实现的原因,另一方面也是因为普通的1F1B中不同stage间的前向反向排布很紧,没有通信重叠的空间。 还要注意流水线气泡的问题,以上面两个配置为例。 第一个配置中:
DP=GPUs/PP/TP=4
MBN=256
MBS=4
GBS=4*256*4=4096
vpp=3
气泡率=(pp-1)/(MBN*vpp+pp-1)=0.039
第二个配置中,由于关闭了vpp,必须加大micro batch number(MBN)来减少气泡率到相近的水平。顺便提一下,在流水线并行中,往往需要设置较大的micro batch number。
DP=GPUs/PP/TP=4
MBN=512
MBS=4
GBS=4*256*2*4=8192
气泡率=(pp-1)/(MBN+pp-1)=0.057
在流水线气泡相近的情况下,可以看到因为流水线通信重叠确实可以带来一定的速度的提升。
这里,顺便说下PP负载均衡的问题。235B的模型一共有94个transformer layer,这样的设计是考虑到最开始的embedding和最后的loss计算都会多消耗一些时间,所以为了防止第一个流水线stage和最后一个成为速度瓶颈,就让第一个和最后一个stage少放一个transformer layer。这样也相当于把embedding和loss计算也当做1个layer来看。
PP并行数的设置#
PP并行数如何设置呢,是否也是越小越好?我们来固定TP和EP,来看不同PP的表现。
配置 |
SeqLen |
GlobalBatchSize |
GPUNum |
TimePerIter (s) |
Tokens/GPU/Second |
|---|---|---|---|---|---|
tp2, ep8, pp8, recompute=select |
4096 |
2048 |
256 |
27.555 |
1189.17 |
tp2, ep8, pp32, vpp3, recompute=select |
4096 |
2048 |
256 |
22.42 |
1461.56 |
可以看到第二个配置pp32速度并没有比pp8低,反而由于开启了vpp能够做pp通信重叠,速度还有提升。这说明了PP的很好的扩展性。
假设一个micro batch的激活值显存为M,对于不开vpp的普通1F1B而言,激活值峰值显存为 pp*M, 而如果开启vpp,激活值峰值显存为 (vpp+1)/vpp * pp * M。
第一个pp8的配置,由于显存基本打满,一旦开启vpp就会由于激活值显存进一步变大而OOM。
所以,PP的数目设置有很大灵活性,可以综合其他的考虑,如EP数、vpp等设置。
重计算#
配置 |
SeqLen |
GlobalBatchSize |
GPUNum |
TimePerIter (s) |
Tokens/GPU/Second |
|---|---|---|---|---|---|
tp2, ep8, pp32, vpp3, recompute=select |
4096 |
2048 |
256 |
22.42 |
1461.56 |
tp1, ep8, pp32, vpp3, recompute=moe |
4096 |
2048 |
256 |
22.946 |
1428.04 |
tp1, ep8, pp32, vpp3, mbs=4, recompute=full |
4096 |
4096 |
256 |
42.537 |
1540.68 |
tp1, ep8, pp32, vpp3, mbs=8, recompute=full |
4096 |
8192 |
256 |
86.186 |
1520.8 |
第一个配置中 recompute=select 是指重计算layernorm和moe中swiglu,即 --recompute-granularity selective --recompute-modules moe_act layernorm。这是类似DeepSeekV3的做法,引入很小的重计算量但是可以省掉一部分激活值显存,这样配置的速度可以近似为没有recompute。
第二个配置中 recompute=moe 是指重计layernorm和moe整个模块,即 --recompute-granularity selective --recompute-modules moe layernorm 。从前面的分析中可以知道,激活值和MLP(即MoE)的显存占了绝大部分,所以这样设置可以节省大量的激活值显存,但是也引入了更多重计算的开销。这里同时将TP从2改为1,即关闭TP。最终和不开启recompute相比(第一个配置)速度相当。
第三个配置中 recompute=full 是每个transformer layer只保留输入的hidden states,其他激活值在反向时重新计算。这带来了更大的开销,但同时节省了更多的显存。由于显存节省所以可以使用更大的MicroBatchSize(这里设置为4),从而提高了计算单元的计算强度。总体上速度比第一个近似不开recompute的配置有明显提升。
但是MicroBatchSize持续变大,速度提升的收益会见顶,这可以看第四个配置的结果来验证。
EP负载不均衡#
前面的实验为了测速都开启了moe强制均衡 --moe-router-force-load-balancing。这是因为如果开启专家并行时 moe路由不均衡,很容易出现OOM的情况,速度也会随之变慢。
对于速度影响到底有多大呢?这里看一个不同capacity(--moe-expert-capacity-factor)的实验。
配置 |
SeqLen |
GlobalBatchSize |
GPUNum |
TimePerIter (s) |
Tokens/GPU/Second |
|---|---|---|---|---|---|
tp4, ep8, deepep, pp8, vpp4, capacity=1 |
4096 |
2048 |
256 |
50.81 |
644.92 |
tp4, ep8, deepep, pp8, vpp4, capacity=2 |
4096 |
2048 |
256 |
51.637 |
634.58 |
tp4, ep8, deepep, pp8, vpp4, capacity=3 |
4096 |
2048 |
256 |
53.734 |
609.82 |
tp4, ep8, deepep, pp8, vpp4, capacity=5 |
4096 |
2048 |
256 |
66.337 |
493.96 |
可以看到随着capacity增大,速度明显变慢,这是因为专家路由不均衡,导致某些专家处理过多的token成为了慢节点,拖慢了整体的速度。 如果capacity设置更大的值,或者直接用token dropless的策略,那么会更慢,而且很容易在某些情况(如特定数据等)下OOM。
最优策略汇总和Benchmark结果#
在尝试多组策略后,分享最优的几组策略如下。
配置 |
SeqLen |
GlobalBatchSize |
GPUNum |
TimePerIter (s) |
Tokens/GPU/Second |
TFlops/GPU |
|---|---|---|---|---|---|---|
tp1, ep8, pp32, vpp3, mbs=4, recompute=full |
4096 |
4096 |
256 |
42.537 |
1540.68 |
228.09 |
tp1, ep8, pp32, vpp3, mbs=8, recompute=full |
4096 |
8192 |
256 |
86.186 |
1520.8 |
225.15 |
tp2, ep8, pp32, vpp3, mbs=4, recompute=full |
4096 |
4096 |
256 |
43.495 |
1506.76 |
223.08 |
tp2, ep8, pp32, vpp3, mbs=1, recompute=select |
4096 |
2048 |
256 |
22.42 |
1461.56 |
216.4 |
tp1, ep8, pp32, vpp3, mbs=1, recompute=moe |
4096 |
2048 |
256 |
22.946 |
1428.04 |
211.52 |
目前的配置大概能到 1500 的 TGS,MFU 大约为 228.09/989.4 = 23% 。
最近,英伟达也对Qwen3 235B模型在256块H100上做过benchmark。 对于主分支代码利用3D混合并行策略,最高速度为 200 TFlops,与我们上面结论相差不多。 另外,还可以看到有趣的两点:一是,主分支代码上如果不用3D并行策略而改用FSDP+recompute策略,速度可达到 276 TFlops;二是,在另外的moe_dev分支上,测试尚未公布的1F1B overlap策略,速度也可以达到276 TFlops。
混合并行最佳实践的建议#
在Megatron上使用混合并行时,有几点建议:
尽量少用TP,除非显存压力很大,必须开启带sequence_parallel的TP。
这本质上是因为PP和EP都不减少激活值显存,所以从这个角度上,最近一些研究减少激活值的PP技术值得关注,比如 ZB-Half, PipeOffload。
EP有两面性,在解决好通信重叠和负载均衡的基础上,开启大EP有正向收益
PP有很好的扩展性,可以灵活设置,但需要考虑Micro Batch Number等避免大的气泡率
recompute/offload等是非常值得尝试的策略,结合更大的Micro Batch Size往往会带来更快的速度